2024,Python爬虫系统入门与多领域实战【官方同步】 0



2024,Python爬虫系统入门与多领域实战
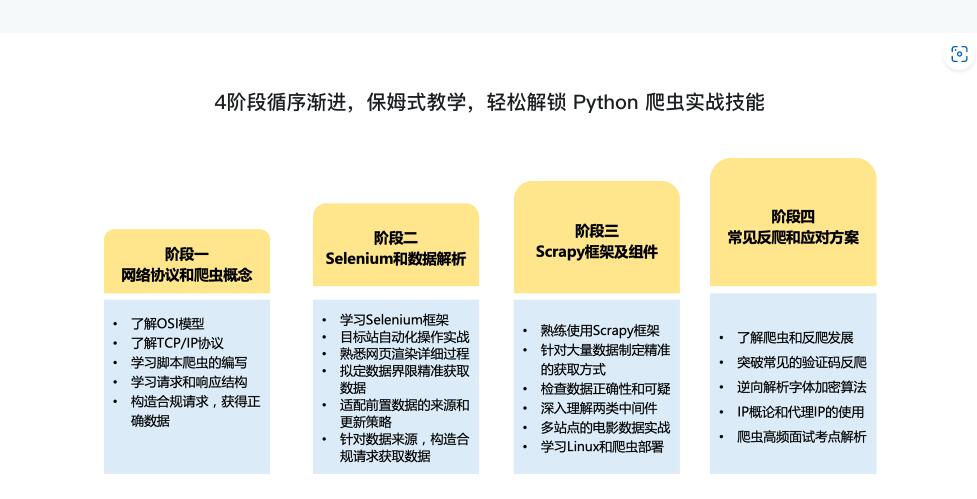
4阶段带你完成从Python爬虫小白,到能力者的蜕变
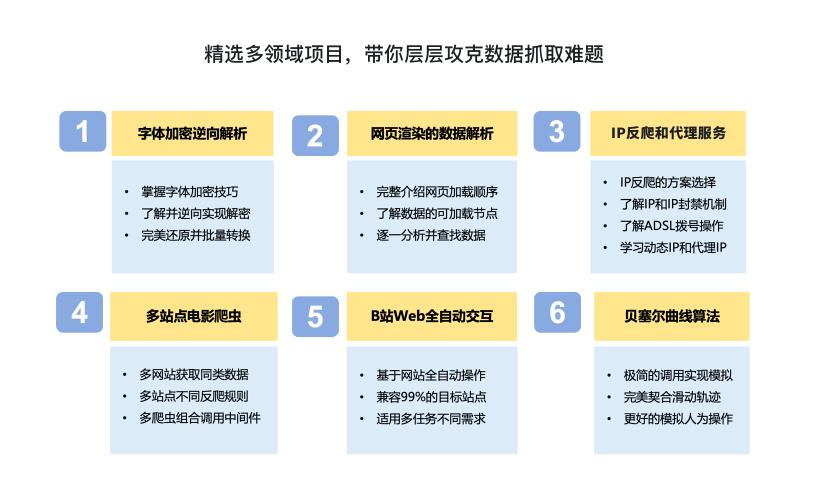
数据时代,越来越多的工作强依赖于数据,而爬虫正是快速获取数据最重要的方式,企业应用中对爬虫相关操作的需求也是越来越多。本课程专为希望系统入门爬虫的同学精心打造,从爬虫基础理论到热门框架应用,从数据解析到常见反爬和应对方案,4阶段带你系统构建爬虫技术体系,精选多领域实战项目,层层深入,带你打牢实用硬技能。
适合人群 对爬虫感兴趣的数据爱好者、开发者;技术提升遇到瓶颈,希望拓宽赛道的工程师
技术储备 熟悉Python基础语法
环境参数 Python 3.9
课程目录
-
第1章 【第一阶段】爬虫概念学习和开发须知(5 节|24分钟)
- 视频1-1 一课带你系统入门Python爬虫.MP4 04:04
- 视频1-2 第一阶段学习安排.MP4 02:26
- 视频1-3 爬虫是什么?能解决什么问题?.MP4 04:01
- 视频1-4 为什么要学Python爬虫开发?.MP4 05:16
- 视频1-5 爬虫开发注意事项.MP4 08:00
-
第2章 爬虫本质是网络请求(8 节|26分钟)
- 视频2-1 爬虫和爬虫工程师.MP4 04:33
- 视频2-2 爬虫的本质.MP4 04:29
- 视频2-3 网络协议-OSI模型介绍.MP4 04:01
- 视频2-4 网络协议- TCPIP协议介绍.MP4 03:48
- 视频2-5 完整的网络请求过程.MP4 05:42
- 视频2-6 HTTP协议概述.MP4 03:16
-
图文:2-7 HTTP协议发展历程介绍
-
图文:2-8 OSI模型知识点介绍
-
第3章 课程相关库介绍(4 节|20分钟)
- 视频3-1 Python的版本说明.MP4 04:46
- 视频3-2 Python的爬虫库介绍.MP4 03:37
- 视频3-3 数据库介绍.MP4 05:24
- 视频3-4 操作系统的介绍和说明.MP4 05:44
-
第4章 从实践入手学习Python爬虫(7 节|69分钟)
- 视频4-1 目标站点分析.MP4 09:23
- 视频4-2 编写脚本爬虫实现需求.MP4 03:40
- 视频4-3 上手编写简单的http请求.MP4 14:23
- 视频4-4 关于响应的数据格式说明和解析方式.MP4 10:35
- 视频4-5 将爬虫数据存储到本地文件.MP4 16:50
- 视频4-6 解析网络请求的详细数据.MP4 07:07
- 视频4-7 解析网络响应的详细信息.MP4 06:24
-
第5章 详细学习requests库和请求构造(6 节|51分钟)
- 视频5-1 requests库和请求数据的重要性.MP4 04:03
- 视频5-2 两个必会的请求方法get和post.MP4 11:07
- 视频5-3 显性参数和隐性参数.MP4 08:59
- 视频5-4 post提交主体数据.MP4 07:28
- 视频5-5 ssl证书的验证问题.MP4 07:20
- 视频5-6 html&txt&json三种数据类型说明.MP4 11:46
-
第6章 【第二阶段】使用Selenium库进行网页交互(13 节|117分钟)
- 视频6-1 PythonSelenium安装介绍.MP4 03:41
- 视频6-2 浏览器驱动的下载和配置.MP4 10:34
- 视频6-3 网页元素的5种定位方式(上).MP4 17:46
- 视频6-4 网页元素的5种定位方式(下).MP4 10:16
- 视频6-5 Selenium点击网页元素.MP4 12:29
- 视频6-6 Selenium获取网页数据.MP4 19:36
- 视频6-7 Selenium的无窗口模式.MP4 07:21
- 视频6-8 Selenium浏览器的懒加载模式.MP4 07:21
- 视频6-9 Selenium执行js代码.MP4 08:48
- 视频6-10 Selenium新建浏览器标签页.MP4 10:17
- 视频6-11 标签页的切换和关闭.MP4 08:41
-
图文:6-12 Chrome版本及对应驱动下载地址
-
图文:6-13 Windows系统环境变量介绍
-
第7章 Selenium实战——B站网站的自动化操作(4 节|74分钟)
- 视频7-1 bilibili站点分析.MP4 04:06
- 视频7-2 Selenium自动化爬取bilibili网站.MP4 19:23
- 视频7-3 增量视频数据的格式和存储.MP4 24:35
- 视频7-4 Selenium增量爬取bilibili网站.MP4 25:55
-
第8章 深入掌握浏览器渲染网页的完整流程(9 节|95分钟)
- 视频8-1 浏览器爬虫和纯脚本爬虫的区别.MP4 04:33
- 视频8-2 网页的形成顺序.MP4 05:27
- 视频8-3 什么是异步数据.MP4 05:22
- 视频8-4 通过浏览器分析网络请求.MP4 13:15
- 视频8-5 源码分析异步数据的来源.MP4 11:44
- 视频8-6 学习调试工具的使用和查找.MP4 14:39
- 视频8-7 获取异步渲染数据.MP4 21:36
- 视频8-8 获取异步请求数据.MP4 10:55
- 视频8-9 异步数据的格式和解析方法说明.MP4 07:02
-
第9章 解析网页数据之xpath语法(9 节|83分钟)
- 视频9-1 如何提取网页内容.MP4 02:57
- 视频9-2 xpath和re的各自优势.MP4 03:31
- 视频9-3 xpath插件安装.MP4 03:29
- 视频9-4 理解xpath节点概念.mp4.MP4 09:30
- 视频9-5 xpath标签检索.mp4.MP4 07:41
- 视频9-6 xpath属性检索方式.MP4 12:13
- 视频9-7 xpath中contains函数的应用.mp4.MP4 10:18
- 视频9-8 理解和使用与或非关系.MP4 09:26
- 视频9-9 xpath解析bilibili网站.MP4 23:48
-
第10章 解析网页数据之正则表达式(6 节|51分钟)
- 视频10-1 正则表达式RE库的查找方法.MP4 10:41
- 视频10-2 正则表达式字符匹配.MP4 07:16
- 视频10-3 正则表达式-字符集合匹配.MP4 08:51
- 视频10-4 正则表达式-数量匹配.MP4 07:42
- 视频10-5 正则表达式-边界匹配.MP4 05:44
- 视频10-6 正则表达式-贪婪和非贪婪模式.MP4 10:21
-
第11章 【第三阶段】从实践入手学习Python爬虫(12 节|82分钟)
- 视频11-1 第三阶段学习安排.MP4 01:52
- 视频11-2 Scrapy框架能解决什么问题.MP4 03:01
- 视频11-3 安装Scrapy框架.MP4 05:30
- 视频11-4 Scrapy完整架构学习.MP4 06:48
- 视频11-5 Scrapy基本模块介绍与工作流程.MP4 02:46
- 视频11-6 Scrapy爬虫文件模板.MP4 12:06
- 视频11-7 Scrapy命令行工具.MP4 10:11
- 视频11-8 创建Scrapy项目爬虫.MP4 06:14
- 视频11-9 Scrapy项目爬虫数据抓取.mp4.MP4 11:05
- 视频11-10 Scrapy调试模式介绍.MP4 05:21
- 视频11-11 启动Scrapy调试模式并测试.mp4.MP4 11:31
- 视频11-12 Scrapy项目多爬虫介绍.MP4 05:25
-
第12章 上手开发Scrapy项目爬虫(9 节|58分钟)
- 视频12-1 明确抓取目标.MP4 03:16
- 视频12-2 创建Scrapy项目.MP4 02:02
- 视频12-3 创建spider爬虫文件.MP4 02:14
- 视频12-4 启动执行Scrapy爬虫.MP4 04:06
- 视频12-5 分析Scrapy的输出日志.MP4 08:56
- 视频12-6 编写并运行爬虫测试.MP4 11:13
- 视频12-7 获取数据并用item结构保存数据.MP4 11:54
- 视频12-8 pipeline管道文件存储数据.MP4 10:17
- 视频12-9 项目总结.MP4 03:48
-
第13章 深入学习Scrapy框架的内置中间件(4 节|15分钟)
- 视频13-1 Scrapy中间件的类型介绍.MP4 04:17
- 视频13-2 Scrapy中间件的内置函数.MP4 02:58
- 视频13-3 Scrapy内置爬虫中间件(一).MP4 04:23
- 视频13-4 Scrapy内置爬虫中间件(二).MP4 03:19
-
第14章 深入学习Scrapy下载器中间件和实战操作(6 节|55分钟)
- 视频14-1 下载器中间件内置函数介绍.MP4 06:09
- 视频14-2 Scrapy框架内置的下载器中间件(一).MP4 04:44
- 视频14-3 Scrapy框架内置的下载器中间件(二).MP4 05:38
- 视频14-4 Scrapy框架内置的下载器中间件(三).MP4 06:08
- 视频14-5 下载器中间件实战训练之User-Agent管理.MP4 09:42
- 视频14-6 下载器中间件实战训练之Cookie管理.MP4 22:08
-
第15章 深入学习Scrapy管道和下载文件(4 节|31分钟)
- 视频15-1 Scrapy pipeline管道.MP4 03:15
- 视频15-2 Scrapy内置filepipeline文件管道.MP4 02:29
- 视频15-3 Scrapy内置imagepipeline图片管道.MP4 04:32
- 视频15-4 pipeline管道实战训练.MP4 20:17
-
第16章 使用Scrapy框架开发电影网站多站点爬虫项目(12 节|138分钟)
- 视频16-1 多站点爬虫实战项目概述.MP4 05:42
- 视频16-2 多站点爬虫的目标站点分析.MP4 05:49
- 视频16-3 单站爬虫自定义下载器配置说明.MP4 05:44
- 视频16-4 多站点爬虫的数据格式定义和管道设计.MP4 03:38
- 视频16-5 针对目标网站开发针对性爬虫及策略(上).MP4 20:43
- 视频16-6 针对目标网站开发针对性爬虫及策略(中).MP4 23:26
- 视频16-7 针对目标网站开发针对性爬虫及策略(下).MP4 14:13
- 视频16-8 针对目标网站开发针对性的下载器及策略.MP4 20:06
- 视频16-9 启动爬虫抓取数据并保存本地(上).MP4 17:29
- 视频16-10 启动爬虫抓取数据并保存本地(下).MP4 17:59
- 视频16-11 项目总结.MP4 02:55
-
图文:16-12 【练习】Scrapy架构爬虫实战
-
第17章 Linux操作系统搭建和应用(6 节|72分钟)
- 视频17-1 Linux版本选择与安装.MP4 07:45
- 视频17-2 Linux远程连接操作.MP4 09:31
- 视频17-3 文件和目录结构.MP4 05:11
- 视频17-4 命令结构介绍.MP4 15:37
- 视频17-5 文件及目录管理.MP4 18:38
- 视频17-6 文件权限说明和管理.MP4 14:33
-
第18章 在Linux系统上部署Scrapy爬虫项目(9 节|121分钟)
- 视频18-1 Linux下安装Python和pip.MP4 14:58
- 视频18-2 Linux下安装MySQL、Redis.MP4 19:59
- 视频18-3 Linux下的scrapyd服务管理.MP4 07:19
- 视频18-4 将爬虫项目部署到scrapyd中.MP4 12:40
- 视频18-5 使用管道将数据写入Redis数据库.MP4 12:55
- 视频18-6 使用管道将数据写入MySQL数据库(上).MP4 13:15
- 视频18-7 使用管道将数据写入MySQL数据库(下).MP4 14:06
- 视频18-8 用网页对scrapyd进行管理.MP4 25:18
-
图文:18-9 【练习】Linux系统安装Scrapyd并部署Scrapyd项目
-
第19章 【第四阶段】了解爬虫发展和反爬概念(4 节|23分钟)
- 视频19-1 第四阶段学习安排.MP4 03:11
- 视频19-2 爬虫的发展.MP4 03:14
- 视频19-3 反爬的概念和定义.MP4 06:10
- 视频19-4 常见的反爬手段.MP4 10:19
-
第20章 常见验证码阶段爬虫和解决方法(8 节|105分钟)
- 视频20-1 验证码的版本发展.MP4 08:43
- 视频20-2 打码平台介绍.MP4 09:02
- 视频20-3 字符验证码和OCR识别(上).MP4 22:54
- 视频20-4 字符验证码和OCR识别(下).MP4 23:14
- 视频20-5 滑块验证码和贝塞尔曲线(上).MP4 20:19
- 视频20-6 滑块验证码和贝塞尔曲线(下).MP4 13:08
- 视频20-7 短信验证码和接码平台.MP4 03:31
- 视频20-8 验证码的终极目标.MP4 03:30
-
第21章 了解Cookie重要性和Cookie管理方法(5 节|32分钟)
- 视频21-1 Cookie的由来本质和功能.MP4 06:35
- 视频21-2 Cookie和Session的区别.MP4 03:13
- 视频21-3 什么是Cookie投毒.MP4 03:43
- 视频21-4 requests的Cookie自动维护.MP4 15:17
- 视频21-5 Scrapy的Cookie中间件.MP4 02:35
-
第22章 学习内容反爬之加密字体逆向解密(5 节|43分钟)
- 视频22-1 字体反爬的由来和介绍.MP4 05:05
- 视频22-2 字体加密的技术原理.MP4 04:09
- 视频22-3 字体映射图解析.MP4 03:53
- 视频22-4 使用Python读取字体文件.MP4 12:25
- 视频22-5 将加密内容还原.MP4 16:33
-
第23章 了解IP概念和代理IP的使用(7 节|55分钟)
- 视频23-1 网络架构概述.MP4 06:29
- 视频23-2 带宽网络介绍.MP4 11:26
- 视频23-3 服务端的请求解析.MP4 05:35
- 视频23-4 爬虫的代理服务器介绍.MP4 07:58
- 视频23-5 固定IP服务器和动态IP服务器.MP4 03:45
- 视频23-6 Linux系统架设请求代理服务器.MP4 07:58
- 视频23-7 Python接入代理服务器代发请求.MP4 11:23
-
第24章 爬虫高频面试考点
-
内容更新中
-
-
第25章 课程总结
-
内容更新中
-
未经允许,禁止转载本站所有原创内容
学习此课程需支付30元,会员免费







